Benchmarking in the Cloud
Since most user data in a social network consist in chat and email messages, the messaging system has to scale up very smoothly. In order to buy time, we had already split it up: Into email messages stored permanently on the one hand, and chat messages stored for 10 days, and delivered via a Redis queue, on the other hand. Now chat messages are a valuable information for a social network (they are a key element of our spam detection system, for instance), and the deletion job itself was becoming a performance bottleneck. So we have been looking for the optimal solution to combine both messaging systems in a scalable way.
The idea was to use a dedicated, shardable database, to spread the load on several machines. Apart from the throughput, key aspects for the choice of a database system are its ease of use, a broad community support, the existence of up-to-date PHP drivers as well as backup and monitoring tools. We’ve evaluated Cassandra and MongoDB, after having rejected other database systems like CouchDB (performing worse according to most benchmarks), HyperTable (too complicated to use and to set up), or HyperDex (lacking community support).
We’ve benchmarked both databases on Amazon EC2 instances for up to 50 million user conversations.
Driving Cassandra with PHP
We wanted to try out Cassandra because it scored much better in benchmarks than MongoDB, and seemed to have more stable and predictable performance characteristics. But it was clear from the beginning that the PHP integration would be a pain… First, you have to know that there is a pretty cool new version 3 of the Cassandra Query Language, which is just like SQL minus joins minus subqueries. But no PHP driver supports it yet! They all are stuck at CQL 2, which is not so nice: A SQL-like query language not even used internally by the Cassandra server, which has to be compiled by the driver to deprecated API calls… Now the problem is that some features you will actually need, like compound indexes, are only available as of CQL 3.
So for all practical purposes, you have to design your Cassandra database with single-column indexes. As a workaround, besides the two columns of what we would have liked to be a compound unique key, we’ve introduced a primary key where we concatenate manually both columns! It is one more line of logic on the client side, it has certainly an impact on the storage performance, but it just worked fine!
As a driver, we’ve found out that we could use PDO as usual if we put MariaDB – the open-source fork of MySQL – as a layer between PHP and Cassandra. The Cassandra Storage Engine, a plug-in for MariaDB, allows you to query Cassandra tables with plain SQL. This was by far the most convenient way of accessing the Cassandra database from PHP!
Benchmark Results
Let us skip the details of the benchmark setup first, so that we can go straight to the results: As expected, Cassandra is scaling up very smoothly, with no noticeable performance drop as the number of conversations increases up to 50 million. MongoDB, on the contrary, shows a clear performance drop which is probably due to the complexity of indexing sub-documents, but still it performs good enough for our purposes. MongoDB is even outperforming Cassandra for “small” databases of less than 10 million conversations, so given its ease of use and the great community support for MongoDB, this will be our choice.
We’ve plotted here the maximal insertion rate, in conversations created per second, as it evolves when the size of the database increases (blue for MongoDB, red for Cassandra):
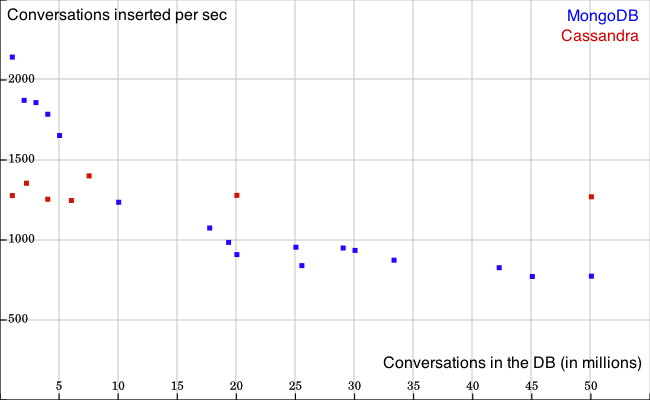
Since reads are extremely fast on both database systems, we’ve only benchmarked the insertion of conversations, which would always be the bottleneck in our use case. Each conversation consists in 20 random messages sent between two random users. We’ve sent batches of full conversations with single queries inserting 1’000 conversations at once (the maximum allowed for SQL queries), in order to avoid network bottlenecks.
We’ve used a total of 10 million users for all conversations, so that we could test the speed of index building on sender and recipients. So at about 5 million conversations, every user is engaged in one conversation, in average. The performance drop of MongoDB above this point is, presumably, due to the complexity of building indexes when users are engaged in several conversations.
Benchmark Architecture
Benchmarking different database servers on a laptop is not that easy, since even the client itself can consume 100% of your CPU sending requests. So we’ve decided to provision two large M3 Amazon EC2 instances to play the role of client and server. This way we could make sure that the limiting factor in this benchmark wasn’t the client, the network or the disk throughput, so that we could actually compare the performance of both databases.
As for the client, we’ve used Mario Casciaro’s Benchpress framework, a Node.js application ideal for simulating high load on the database server. We’ve sent in parallel several bulk requests of 1’000 conversations with 20 messages each, with random user IDs on which indexes were created.
For the server, it was important to provision a high I/O throughput of 1’000 IOPS in order to hit the actual database limit. In order to optimize disk access, we’ve also put the Cassandra database on a dedicated drive, separated from its commit logs and from the binary logs of MariaDB.
All machines were provisioned using Vagrant and the Vagrant AWS plug-in.
This made provisioning and freeing both machines and storage a breeze:
Just run vagrant up to provision a new machine and vagrant destroy when you’re done, and here you go!
Here is the Vagrantfile we’ve been using to provision the server:
Vagrant.configure('2') do |config|
config.vm.box = 'cargomedia/debian-7-amd64-default'
config.ssh.forward_agent = true
config.vm.provider :aws do |aws, override|
override.ssh.username = 'admin'
override.ssh.private_key_path = '~/.ssh/benchmark.pem'
aws.region = 'eu-west-1'
aws.instance_type = 'm3.large'
aws.access_key_id = '...'
aws.secret_access_key = '...'
aws.keypair_name = '...'
aws.security_groups = '...'
aws.tags = {
'Name' => 'Benchmark Server MongoDB'
}
aws.block_device_mapping = [
{
'DeviceName' => "/dev/sdb",
'VirtualName' => "data",
'Ebs.VolumeSize' => 500,
'Ebs.DeleteOnTermination' => true,
'Ebs.VolumeType' => 'io1',
'Ebs.Iops' => 1000
}
]
end
config.vm.provision 'shell', inline: [
'cd /vagrant',
'./install.sh',
'./setup-storage.sh',
].join(' && ')
end
It relies on two simple setup scripts, one to install MongoDB and system monitoring tools:
#!/bin/bash
# Installing MongoDB:
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv 7F0CEB10
echo 'deb http://downloads-distro.mongodb.org/repo/debian-sysvinit dist 10gen' | sudo tee /etc/apt/sources.list.d/mongodb.list
sudo apt-get update
sudo apt-get -y install mongodb-10gen
# Installing monitoring tools:
sudo apt-get install iotop screen
and one to prepare the disk where the database is going to be stored:
#!/bin/bash
# Format and mount external drive
sudo mkfs.ext3 /dev/xvdb
sudo mount /dev/xvdb /mnt
sudo mkdir -p /mnt/mongodb
sudo chmod -R 0777 /mnt
# Setup MongoDB to store databases there
sudo /etc/init.d/mongodb stop
sudo grep -v "^dbpath" /etc/mongodb.conf > /tmp/mongodb.conf
sudo cp /tmp/mongodb.conf /etc/mongodb.conf
sudo echo "dbpath=/mnt/mongodb" >> /etc/mongodb.conf
sudo /etc/init.d/mongodb start
# Wait for MongoDB to become available
sleep 10
Setting up access to Cassandra through MariaDB
In order to be able to “talk” SQL with the Cassandra server, we’ve used MariaDB’s Cassandra Storage Engine plug-in. This requires an extra step of configuration to define a “mapping” between Cassandra’s column families and MariaDB table structures.
The installation of Cassandra and MariaDB is quite straightforward, but still it is a bit more effort than installing MongoDB:
#!/bin/bash
# Installing OpenJDK 7:
sudo apt-get -y install default-jdk default-jre openjdk-6-jre openjdk-6-jdk openjdk-7-jre openjdk-7-jdk java-common
sudo update-java-alternatives -s java-1.7.0-openjdk-amd64
# Installing JNA:
sudo apt-get -y install libjna-java
# Installing Cassandra:
curl -L http://debian.datastax.com/debian/repo_key | sudo apt-key add -
echo 'deb http://debian.datastax.com/community stable main' | sudo tee -a /etc/apt/sources.list.d/cassandra.sources.list
sudo apt-get update
sudo apt-get -y install dsc20
# Installing MariaDB:
# Setting up root password non-interactively
echo 'maria-db-server mysql-server/root_password password root' | sudo debconf-set-selections
echo 'maria-db-server mysql-server/root_password_again password root' | sudo debconf-set-selections
sudo apt-key adv --recv-keys --keyserver keyserver.ubuntu.com 0xcbcb082a1bb943db
sudo add-apt-repository 'deb http://mirrors.n-ix.net/mariadb/repo/10.0/debian wheezy main'
sudo apt-get update
sudo apt-get -y install python-software-properties mariadb-server
# Installing monitoring tools:
sudo apt-get install iotop screen
# Format and mount external drive
sudo mkfs.ext3 /dev/xvdb
sudo mount /dev/xvdb /mnt
sudo mkdir -p /mnt/cassandra/data
sudo chmod -R 0777 /mnt
# Setup Cassandra to store databases there (NOT commit logs!)
sudo /etc/init.d/cassandra stop
sudo sed -i 's/\/var\/lib\/cassandra\/data/\/mnt\/cassandra\/data/g' /etc/cassandra/cassandra.yaml
sudo /etc/init.d/cassandra start
# Wait for Cassandra to become available (replaying commit logs for system tables on the new storage location)
sleep 10
# Allow remote access to MariaDB and limit the bin log size
sudo /etc/init.d/mysql stop
sudo sed -i 's/bind-address[[:space:]]*=.*/bind-address=0.0.0.0/g' /etc/mysql/my.cnf
echo -e '\n[mysqlbinlog]\nopen-files-limit = 16' | sudo tee -a /etc/mysql/my.cnf
sudo /etc/init.d/mysql start
# Wait for MariaDB to become available
sleep 10
cqlsh -f setup.cql
mysql -u root --password=root < setup.sql
The subtle part is rather the database setup itself. First, you have to define column families with Cassandra, which we’ve done with the following CQL 3 script:
CREATE SCHEMA IF NOT EXISTS "sk"
WITH replication = { 'class' : 'SimpleStrategy', 'replication_factor' : 1 };
USE "sk";
CREATE TABLE IF NOT EXISTS "sk_conversation" (
"id" uuid PRIMARY KEY,
"userId" int,
"createStamp" int,
"messageList" text
) WITH COMPACT STORAGE;
CREATE INDEX IF NOT EXISTS ON "sk_conversation" ("userId");
CREATE TABLE IF NOT EXISTS "sk_conversationRecipient" (
"KEY" ascii PRIMARY KEY,
"conversationId" uuid,
"userId" int,
"blocked" boolean,
"deleted" boolean,
"read" boolean,
"sendStamp" int,
"receiveStamp" int
) WITH COMPACT STORAGE;
CREATE INDEX IF NOT EXISTS ON "sk_conversationRecipient" ("conversationId");
CREATE INDEX IF NOT EXISTS ON "sk_conversationRecipient" ("userId");
The “compact storage” option is needed for compatibility to MariaDB, and implies that you cannot use compound indexes, so you have to index every single column you would like to query upon.
As a workaround, we’ve added a primary key to the table sk_conversationRecipient in which we’ve concatenated manually the content of the columns conversationId and userId, which should build a unique key.
Then you have to tell MariaDB and the Cassandra SE how to map these column families to SQL table structures, in order for them to compile SQL queries to Cassandra requests:
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%'
IDENTIFIED BY 'root';
FLUSH PRIVILEGES;
INSTALL PLUGIN cassandra SONAME 'ha_cassandra.so';
CREATE DATABASE IF NOT EXISTS `sk`;
USE `sk`;
CREATE TABLE IF NOT EXISTS `sk_conversation` (
`id` CHAR(36) PRIMARY KEY,
`userId` INT,
`createStamp` INT,
`messageList` BLOB
)
ENGINE = cassandra thrift_host = '127.0.0.1' keyspace = 'sk' column_family = 'sk_conversation';
CREATE TABLE IF NOT EXISTS `sk_conversationRecipient` (
`KEY` VARCHAR(47) PRIMARY KEY,
`conversationId` CHAR(36),
`userId` INT,
`blocked` BOOL,
`deleted` BOOL,
`read` BOOL,
`sendStamp` INT,
`receiveStamp` INT
)
ENGINE = cassandra thrift_host = '127.0.0.1' keyspace = 'sk' column_family = 'sk_conversationRecipient';
From now on, you are able to access both Cassandra and MyISAM or InnoDB tables with the same client, and the same SQL queries, through MariaDB. From what we could see, it performs very well, so if you don’t need all too specific NoSQL features, that’s a great way to move parts of your data to Cassandra!
We hope this benchmark will help you choose the best NoSQL database system to fit your needs, and we would be happy to hear about your experiences with the scalability of NoSQL databases!